ORM使用レビュー:SQLAlchemyなどのクエリ最適化観点
はじめに
SQLAlchemyをはじめとするPythonのORMは、データアクセス層の抽象化と保守性向上に貢献する一方で、実行時のクエリ最適化がコードから読み取りづらくなるという特性がある。
レビューアーはこの非可視性に立ち向かい、パフォーマンス劣化を未然に防ぐ構造的なレビュー判断を下す必要がある。
本記事では、SQLAlchemyを主軸に、ORMを用いたクエリ処理におけるレビュー観点を体系的に整理する。
ORMレビューの本質:抽象化の恩恵と代償
ORMの使用は、手続き的なSQL構文をPythonコードへと抽象化し、記述量削減・移植性向上・保守性向上をもたらす。
だがその抽象化の代償として、生成されるSQLクエリの挙動や効率性がコードから直接は見えないという課題がある。
ORM(Object Relational Mapper)とは、オブジェクト指向プログラミングにおけるオブジェクトと、リレーショナルデータベースのテーブルとのマッピングを自動化する仕組み。SQLAlchemyやDjango ORMなどが代表例。
レビューアーはこの「非可視な実行コスト」を意識し、次のような視点でチェックを行う必要がある。
- クエリが暗黙に何回発行されているか
- JOINやプリフェッチ処理が意図通り最適化されているか
- 非効率なフィルタ処理が発生していないか
- リレーションの遅延評価が意図と合っているか
典型的な落とし穴:N+1問題の早期検出
SQLAlchemyにおいて最も典型的なパフォーマンス劣化パターンが N+1問題である。
これは、あるエンティティをループで取得する際に、各子要素の取得が別クエリとして逐次実行されることによって発生する。
# ユーザー一覧を取得し、各ユーザーの所属チーム名を表示
users = session.query(User).all()
for user in users:
print(user.team.name) # チームごとに追加クエリが発行される@Reviewer: ループ内でリレーションにアクセスしているが、事前に `joinedload` などでの最適化がされていないため、N+1問題の発生が懸念されます。このようなケースでは、以下のようにjoinedloadを用いたクエリの最適化が求められる。
from sqlalchemy.orm import joinedload
users = session.query(User).options(joinedload(User.team)).all()遅延ロード vs 即時ロード:その設計意図は妥当か?
SQLAlchemyではリレーションを読み出す際に lazy='select' や lazy='joined' といったローディング戦略を選択できる。
ここで問題となるのは、実際のアクセスパターンとローディング戦略が一致していない設計である。
リレーション属性を読み込む際に、その読み込み方法(別クエリにするか、JOINで一括にするか)を定義する設定。lazy='select' は遅延ロード、lazy='joined' は即時ロード。
class User(Base):
...
team = relationship("Team", lazy='select') # 遅延ロード@Reviewer: 本コードでは、アクセスパターン上 `team` は必ず参照されるように見受けられます。`lazy='joined'` の検討による事前ロードがパフォーマンス上有利です。結合戦略とフィルタ処理の分離:可視性の欠如
ORM設計では、結合戦略(JOIN)とWHERE句(フィルタ)の構造がコード上分離されやすい。
このことが、生成クエリの意図と実際の差異を見逃す原因となる。
session.query(User).join(Team).filter(Team.name == 'Sales').all()一見正しく見えるが、複雑なリレーション構造や外部結合(outerjoin)を伴う場合、JOIN条件の不足がパフォーマンスや正確性に影響する。
@Reviewer: `join()`句の対象が暗黙になっており、複数JOINが連鎖する設計では意図が不明確になります。明示的な条件指定と結合順の妥当性を確認してください。可視化のすすめ:PlantUMLによるリレーション構造図
以下は、User と Team の間に one-to-many のリレーションが存在する典型構造である。
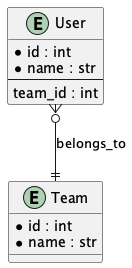
このような構造をレビュー時に図示することで、結合関係とフィールドの参照方向が明確になり、クエリ設計の意図と実態を一致させる手がかりとなる。
サブクエリ vs JOIN:構造的選択がレビュー対象に
ORMでは複雑な集約やフィルタを行う際、JOINによる1回のクエリと、サブクエリを組み合わせる多段構造の選択がしばしば発生する。
たとえば、特定の条件に合致するチームに所属するユーザーのみを取得したい場合:
subq = session.query(Team.id).filter(Team.name == 'Sales').subquery()
users = session.query(User).filter(User.team_id.in_(subq)).all()この構造は可読性は高いが、JOINで代替できる場合、クエリの数や処理効率に差が生まれる可能性がある。
@Reviewer: サブクエリによるフィルタは読みやすいものの、DBエンジンによってはJOINの方が効率的になるケースがあります。Explain結果を元に評価するのが望ましいです。実行クエリの確認とEXPLAINの活用
レビューアーは、ORMコードの挙動を想像するだけでなく、実際に発行されるSQLを確認することが求められる。
SQLAlchemyでは以下のようにしてSQLをログ出力できる。
engine = create_engine(DB_URL, echo=True)また、実行クエリに対する EXPLAIN の確認も有効であり、以下の観点でレビューする。
- 使用インデックスの有無と選定
- フルスキャンになっていないか
- サブクエリの展開方法
- 結合順序と結合方式(Nested Loop / Hash Join)
ORMをレビューで扱う際の最終チェック観点
最後に、レビューアーとしてチェックすべき観点を簡潔に整理する。
- リレーションアクセスでN+1問題が発生していないか?
lazy設定とアクセス頻度が整合しているか?- 結合構造とWHERE条件の意図が一致しているか?
- サブクエリがJOINで代替できる場面ではないか?
- 実行SQLとExplainによる実効性確認がされているか?
おわりに
SQLAlchemyをはじめとするORMは、抽象化による開発効率の向上と引き換えに、レビュー時の可視性の欠如という構造的な課題を抱えている。
その中でも、N+1問題・遅延ロード・JOIN構造などは、静的にコードを読むだけでは発見しづらく、設計意図と実行時の挙動とのズレを見抜く力が求められる。
レビューアーは単にORMコードを「Pythonコードとして」見るのではなく、背後にあるSQL構造とパフォーマンスコストを意識する視点を持ち続ける必要がある。