Python|プロファイリングによる性能責任の特定方法
この記事のポイント
- プロファイリング結果の読み解き方をレビュー視点で整理できる
- ボトルネックの責務整理・設計臭を見抜く技法を学べる
- 実務性能設計の整理文化を体系化できる
- PlantUMLで責務依存構造を可視化整理できる
そもそもプロファイリングとは
プロファイリング(profiling)は「プログラム実行中の性能特性を定量計測する技法」です。
Python標準では cProfile や profile モジュールが利用可能です。
- 実行時間計測(関数別・呼び出し回数別)
- 呼び出し階層(call graph)取得
- 性能ボトルネックの定量分析
- 設計責務の肥大検出に活用
cProfile基本例
import cProfile
def heavy_process():
...
cProfile.run("heavy_process()")- 実行経路全体の計測結果を出力
- 純粋なソース読みより設計責務を発見しやすい
なぜこれをレビューするのか
プロファイリングは「設計臭の事後可視化」に直結します。
レビューアーは以下の整理視点を持つ必要があります。
レビューアー視点
- 実際の負荷がどの責務に集中しているか
- 期待設計と実態性能責任が乖離していないか
- 責務間の肥大・責任混入が発生していないか
- 計測粒度が適切に分解されているか
- 性能責任を設計境界内に分離できるか
開発者視点
- ソース上の「重そうな部分」予想が外れやすい
- 計測出力が多すぎて読めなくなりがち
- 設計整理不足のまま実行最適化だけ行いがち
- キャッシュ導入など局所対応で崩壊を誘発しやすい
プロファイリング崩壊の典型設計臭
崩壊しやすいパターン
- 重い処理が1関数に肥大集中
- 複合API内でI/O/計算/検証が混在
- 外部API呼出が呼び出し階層深部に隠蔽
- 例外制御系統に意図外性能責任が集中
- ループ内部でオブジェクト再生成が多発
崩壊例:責務混在集中型
混在集中例
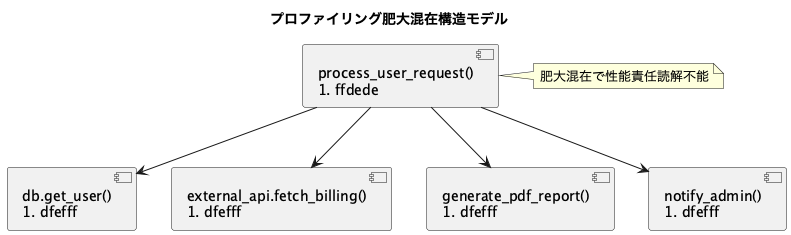
def process_user_request(user_id):
user = db.get_user(user_id)
if not user.is_active:
raise UserInactiveError()
billing_info = external_api.fetch_billing(user)
report = generate_pdf_report(user, billing_info)
notify_admin(report)
@ReviewerDB取得、API呼出、PDF生成、通知責務が全て混在しています。責務分離整理を優先してください。
問題点
- 性能調査時に原因特定困難
- ボトルネック分離不能化
崩壊構造モデル:責務肥大混在構造
プロファイリング活用設計整理の原則
以下の責務整理文化が有効です。
① 責務粒度分離文化
- 計測粒度は責務単位に切り出す
② 外部依存顕在化文化
- I/O/通信/DB/API呼出を分離管理
③ コスト項目分類文化
| 責務種別 | 主コスト要素 |
|---|---|
| 計算系 | CPU負荷 |
| I/O系 | 待機時間 |
| API系 | ネットワーク遅延 |
| 検証系 | 例外制御コスト |
④ 重心責任の明示文化
- 責任所在をコントロール層に集約整理
⑤ 性能境界責任文化
- API境界責任として SLA設計整理
改善例:責務分離整理版
責務分離版
def get_user_info(user_id):
user = db.get_user(user_id)
if not user.is_active:
raise UserInactiveError()
return user
def get_billing_info(user):
return external_api.fetch_billing(user)
def generate_report(user, billing_info):
return generate_pdf_report(user, billing_info)
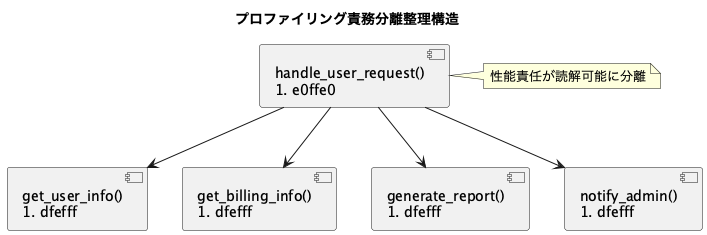
def handle_user_request(user_id):
user = get_user_info(user_id)
billing_info = get_billing_info(user)
report = generate_report(user, billing_info)
notify_admin(report)「呼出経路を直列分離する文化」
レビューアーは「関数責務1原則文化」を徹底確認すると性能設計が読解可能化されます。
改善構造モデル:責務分離整理
良くない実装例: ケース1(ループ副作用混在)
ループ副作用例
def process_batch(user_ids):
reports = []
for uid in user_ids:
user = db.get_user(uid)
report = generate_pdf_report(user)
reports.append(report)
return reports
@Reviewerループ内部にDB・生成副作用が混在しています。分離整理し性能評価可能構造にしてください。
問題点
- DB呼出位置が隠蔽
- 集中負荷発生位置が見えない
改善例:ループ分離整理
ループ分離版
def fetch_users(user_ids):
return [db.get_user(uid) for uid in user_ids]
def generate_reports(users):
return [generate_pdf_report(user) for user in users]
def process_batch(user_ids):
users = fetch_users(user_ids)
reports = generate_reports(users)
return reports- 各処理責務を計測単位で分離
良くない実装例: ケース2(例外系計測抜け)
例外計測漏れ例
def process(user_id):
user = db.get_user(user_id)
if not user.is_active:
return # 無音返却
return generate_pdf_report(user)
@Reviewer例外・異常系が静かに抜け性能計測対象外になります。例外経路も明示検証してください。
問題点
- 異常系処理コスト不透明
- 性能境界の評価不能
改善例:例外経路顕在化
例外経路整理版
def process(user_id):
user = db.get_user(user_id)
if not user.is_active:
raise UserInactiveError()
return generate_pdf_report(user)- 異常処理も計測統制下に統合
良くない実装例: ケース3(コントローラ集中型)
コントローラ集中例
def handle(user_id):
# 全処理集中
user = db.get_user(user_id)
billing = api.fetch(user)
report = generate_pdf_report(user, billing)
log_store.save(report)
@Reviewer全処理を集中保持して性能責務混在しています。処理責務段階分離を行ってください。
問題点
- 集中コントローラ化
- 読解・調整困難化
観点チェックリスト
まとめ
プロファイリング設計は「性能責任の整理文化そのもの」です。
レビューアーは「責務分離文化・計測統制文化・経路可視文化」を徹底教育することで、
長期運用に耐える高信頼性能設計を築けます。