Python|パラメータ化テストで網羅性を保証する設計整理法
この記事のポイント
- パラメータ化テストの設計整理をレビュー視点で体系理解できる
- 網羅性保証と設計臭の読み解きポイントを学べる
- 実務でのテスト網羅整理文化を体系化できる
- PlantUMLでパラメータ化の依存構造を可視化整理できる
そもそもパラメータ化テストとは
pytestでは@pytest.mark.parametrizeデコレーターを用いることで、
複数パターンの入力と期待値を一覧形式で列挙して実行する仕組みが提供されます。
pytestパラメータ化基本例
import pytest
@pytest.mark.parametrize("a,b,expected", [
(1, 2, 3),
(5, 5, 10),
(0, 100, 100)
])
def test_add(a, b, expected):
assert a + b == expected- テスト関数1つで複数パターンを一括管理
- 網羅性・可読性・レビュー性が向上しやすい構造
なぜこれをレビューするのか
パラメータ化は便利である反面、「安直なパターン列挙の乱用設計臭」が発生します。
レビューアーは以下の観察視点を持つ必要があります。
レビューアー視点
- パターン設計が網羅戦略に基づいているか
- 異常系・境界系が欠落していないか
- テストケースの意味が読解可能になっているか
- 入力データ定義が肥大化していないか
- 組合せ爆発になっていないか
開発者視点
- 書きやすいため安易にケース羅列を増やしがち
- 単純直列化で境界・異常系が抜けやすい
- 長大なparametrizeリスト化で読解困難
- 外部ExcelやCSV読み込みで分離困難
パラメータ化崩壊の典型設計臭
崩壊しやすいパターン
- 正常系だけ並列羅列(異常・境界が消失)
- 数百行に及ぶparametrizeリスト
- 入力条件名が無名tupleで意図不明
- 重複パターン混入で読解困難化
- 組合せ生成で実行時間爆発
崩壊例:無名羅列型
無名羅列崩壊例
@pytest.mark.parametrize("a,b,expected", [
(1, 2, 3),
(10, 20, 30),
(100, 200, 300),
(1000, 2000, 3000),
(10000, 20000, 30000),
# 増殖中...
])
def test_add(a, b, expected):
assert a + b == expected
@Reviewer入力パターンが無名羅列で意図判読が困難です。境界・異常系含む設計整理を行ってください。
問題点
- 意図(境界/異常系/代表値)が判読不能
- 仕様変更時にどこに影響出るか把握困難
崩壊構造モデル:羅列型肥大構造
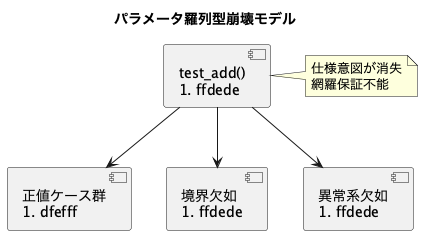
パラメータ化設計整理の原則
以下の設計責務整理文化が有効です。
① 網羅戦略の設計宣言
- 正常系、境界値、異常系を明示区分
② 命名付きパターン文化
- parametrizeにID付与(ids=)
③ 境界優先文化
- パターン数より境界探索を優先
④ 組合せ制御文化
- itertools.productの暴走抑止
- 全網羅より代表値文化
⑤ データ駆動分離文化
- パターン定義は独立変数群に整理分離
改善例:設計宣言整理版
改善整理例
import pytest
@pytest.mark.parametrize(
"a,b,expected",
[
pytest.param(1, 2, 3, id="normal-small"),
pytest.param(100, 200, 300, id="normal-large"),
pytest.param(0, 0, 0, id="boundary-zero"),
pytest.param(-1, -2, -3, id="negative"),
pytest.param(999999999, 1, 1000000000, id="max-boundary"),
]
)
def test_add(a, b, expected):
assert a + b == expected「網羅戦略宣言文化+ID命名文化」
レビューアーは「全ケース意図が説明可能か」を常に確認すると設計臭抑止できます。
改善構造モデル:責務分離整理
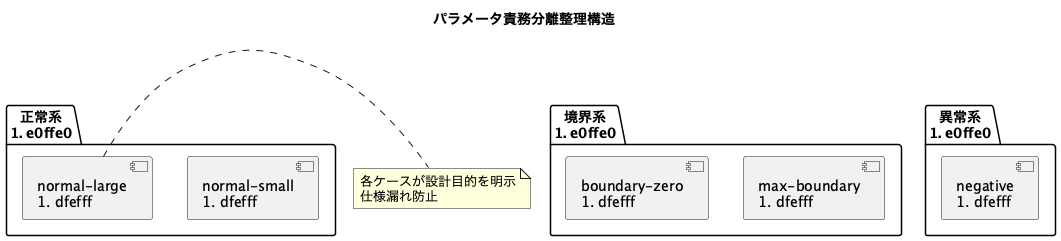
良くない実装例: ケース1(組合せ暴走)
組合せ暴走例
import pytest
import itertools
a_values = [1, 10, 100]
b_values = [2, 20, 200]
@pytest.mark.parametrize("a,b", list(itertools.product(a_values, b_values)))
def test_add(a, b):
assert a + b >= 0
@Reviewer組合せ膨張で読解困難化しています。代表値抽出整理を優先してください。
問題点
- 読解負荷上昇
- 実行時間爆発
- 仕様網羅保証消失
良くない実装例: ケース2(外部CSV肥大)
外部肥大例
import pytest
import csv
@pytest.mark.parametrize("a,b,expected", list(csv.reader(open("test_data.csv"))))
def test_add(a, b, expected):
assert int(a) + int(b) == int(expected)
@Reviewer外部ファイル肥大でレビュー不能化しています。設計網羅意図をテスト側に残してください。
問題点
- 仕様設計責任が外部化
- ソースレビュー不能化
改善例:データ駆動整理版
データ分離整理版
TEST_CASES = [
(1, 2, 3, "normal-small"),
(100, 200, 300, "normal-large"),
(0, 0, 0, "boundary-zero"),
(-1, -2, -3, "negative"),
]
@pytest.mark.parametrize("a,b,expected,test_id", TEST_CASES)
def test_add(a, b, expected, test_id):
assert a + b == expected- データ群はソース内に分離宣言
- レビュー容易性を維持
観点チェックリスト
まとめ
パラメータ化テスト設計は「網羅文化の整理技法」そのものです。
レビューアーは「網羅宣言文化・粒度設計文化・レビュー可読文化」を育成指導することで、長期保守に耐える堅牢なテスト設計を育てられます。