Python|concurrent.futuresでスレッド責任を整理する考え方
この記事のポイント
- concurrent.futuresを安全に設計するレビュー観点を整理する
- スレッド起動責任・完了監視責任・例外回収責任を分離する
- 実務レビューで指摘が必要な設計誤謬を具体例で学習する
そもそもconcurrent.futuresとは
Pythonでは、GILの制約がありつつもI/Oバウンド処理等に対してスレッドを活用する場面が存在します。
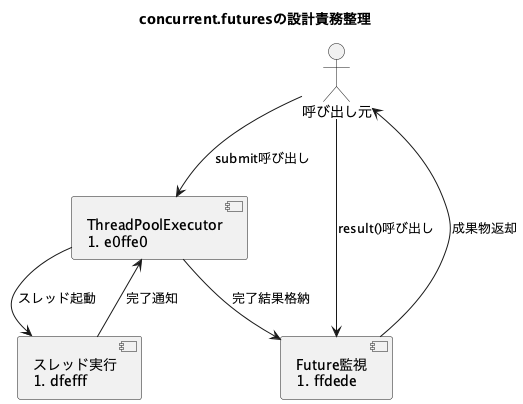
その際に標準ライブラリの concurrent.futures が提供するスレッド管理機能は、以下の責任分離を支援します。
-
Executor(実行器)責任
スレッド生成・破棄のライフサイクル管理 -
Future(将来値)責任
実行結果の回収・監視・例外通知
実務レビューでは「スレッド化すれば速くなる」という短絡的理解ではなく、この責任境界を意識することが重要です。
なぜこれをレビューするのか
スレッド処理は設計が崩れると以下のような典型的な問題が頻発します。
- スレッドプール枯渇
- 未回収Futureの放置
- 例外通知の消失
- キャンセル設計欠如
- スレッド競合の責任未整理
レビューアー視点
レビューアーは以下の切り口で設計責任を読解します。
- Executorの管理責任が集中管理されているか
- Futureの監視・例外処理が明示されているか
- スレッド化すべき対象粒度が適切か(細かすぎ・大きすぎ問題)
- プールサイズと最大同時スレッド上限が調整設計されているか
開発者視点
開発者は「手軽なスレッド化API」としての側面から脱却し、ライフサイクル・回収責任まで含めた設計全体像を意識する必要があります。
良い実装例
正常設計例:責務分離
import concurrent.futures
import requests
from typing import List
class ApiClient:
def __init__(self, base_url: str):
self.base_url = base_url
def fetch(self, endpoint: str) -> dict:
response = requests.get(f"{self.base_url}/{endpoint}", timeout=5)
response.raise_for_status()
return response.json()
class ApiRequestLog:
def __init__(self, request_id: str, endpoint: str, client_ip: str, response_code: int, requested_at: str):
self.request_id = request_id
self.endpoint = endpoint
self.client_ip = client_ip
self.response_code = response_code
self.requested_at = requested_at
def fetch_and_log(client: ApiClient, endpoint: str, logger) -> ApiRequestLog:
try:
result = client.fetch(endpoint)
log = ApiRequestLog(
request_id=result["id"],
endpoint=endpoint,
client_ip=result["client_ip"],
response_code=200,
requested_at=result["timestamp"]
)
logger.save(log)
return log
except Exception as e:
logger.error(f"API呼び出し失敗: {e}")
raise
def orchestrator():
client = ApiClient("https://example.com/api")
logger = SomeLogger()
endpoints = ["user/123", "user/456", "user/789"]
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
futures = {
executor.submit(fetch_and_log, client, ep, logger): ep for ep in endpoints
}
for future in concurrent.futures.as_completed(futures):
endpoint = futures[future]
try:
result = future.result()
print(f"{endpoint}: 正常完了 {result}")
except Exception as e:
print(f"{endpoint}: 失敗 {e}")
orchestrator()良い理由
- Executorの管理責任がwith文により集約されている
- Futureの監視と例外通知責任が回収設計に組み込まれている
- スレッドプールサイズが適切に調整可能
レビュー観点
- Executorスコープの管理責任は集中管理されているか
- Future例外は必ずresult()で回収されているか
- 実行粒度が極端に小さくスレッドコスト過大化していないか
- プール枯渇によるデッドロック可能性が排除されているか
- スレッド安全でないリソース(DB・ログ・状態共有)の並列利用責任が整理されているか
良くない実装例: ケース1
問題例: Future放置による例外未回収
import concurrent.futures
import requests
class ApiClient:
def __init__(self, base_url: str):
self.base_url = base_url
def fetch(self, endpoint: str) -> dict:
response = requests.get(f"{self.base_url}/{endpoint}", timeout=5)
response.raise_for_status()
return response.json()
def main():
client = ApiClient("https://example.com/api")
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
for ep in ["user/123", "user/456", "user/789"]:
executor.submit(client.fetch, ep)
@Reviewersubmit後のFutureオブジェクトを保持せずに破棄しています。失敗時の例外が消失し障害検知できません。Futureは必ず回収・監視してください。
main()問題点
- submit後のFutureを無視している
- 例外発生時に検知不可
- 障害調査困難
改善例
改善後: Future監視設計
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
futures = [executor.submit(client.fetch, ep) for ep in ["user/123", "user/456", "user/789"]]
for future in concurrent.futures.as_completed(futures):
try:
result = future.result()
print(result)
except Exception as e:
print(f"失敗: {e}")設計補足
- submit後は必ずFutureを保持する
- as_completedにより順次結果を監視可能
- 例外発生も漏れなく捕捉可能
良くない実装例: ケース2
問題例: Executorスコープ放置
import concurrent.futures
import requests
executor = concurrent.futures.ThreadPoolExecutor(max_workers=3)
class ApiClient:
def fetch(self, endpoint: str):
response = requests.get(endpoint, timeout=5)
return response.json()
def api_call():
client = ApiClient()
future = executor.submit(client.fetch, "https://example.com/api/user")
return future
future = api_call()
@ReviewerExecutorのライフサイクルがグローバルに常駐し続けています。プロセス終了までスレッドリソースを握り続ける危険があります。with構文でスコープ管理しましょう。
問題点
- Executorがグローバル常駐しプロセス終了まで残存
- スレッドリーク原因
- 終了保証困難
改善例
改善後: Executorスコープ閉鎖設計
def api_call():
client = ApiClient()
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
future = executor.submit(client.fetch, "https://example.com/api/user")
return future.result()設計補足
- Executorはスコープ内閉鎖管理
- スレッド残留リスクを排除
- プール閉鎖保証で安全性向上
PlantUML設計イメージ
観点チェックリスト
まとめ
concurrent.futuresは「楽にスレッド化できる」APIであるがゆえに、設計責任を曖昧化しやすい危険性を持っています。レビューアーは、Executor責任・Future責任・リソース競合責任の3層で責務分離を読解し、安易なスレッド化がシステム全体に悪影響を及ぼさないかを常に設計段階で補強する役割が求められます。