Collector応用 - partitioningBy, collectingAndThen, reducing の設計判断とレビュー視点
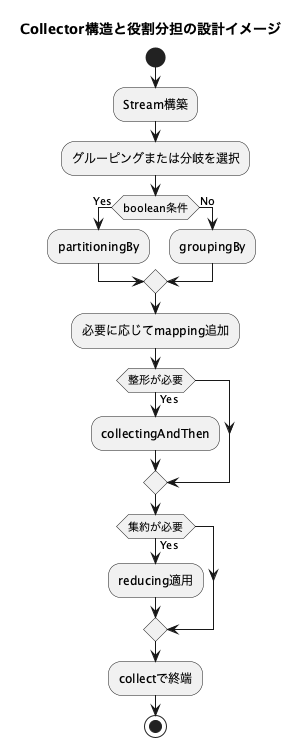
1. partitioningByの設計的特徴とgroupingByとの構造的違い
partitioningByは、Streamの要素をboolean条件で「真/偽」の2つのグループに分けるCollectorです。
一見groupingBy(predicate)と似ていますが、生成されるMap構造・初期化・目的の表現性が根本的に異なります。
1.1 基本構造
Map<Boolean, List<User>> result =
users.stream().collect(Collectors.partitioningBy(User::isActive));これは「trueな要素」「falseな要素」を持つMapに分離されます。
partitioningByは“真/偽の意味的分離”を強調したい時に向いている。
groupingByとは意図表現の重みが異なる。
1.2 groupingByとの比較
Map<Boolean, List<User>> result =
users.stream().collect(Collectors.groupingBy(User::isActive));このコードでも構造は似ますが:
partitioningByはMapのkeyが必ずtrue/falseのみgroupingBy(Boolean::valueOf)ではMapのkeyにnullが含まれる可能性がある(nullable predicate)- 並列処理・初期サイズ・最適化がCollector側で異なる
レビュー観点
- 条件が明確にbooleanで表現できるか?→
partitioningBy - 値がboolean“以外”のグルーピングになる可能性があるか?→
groupingBy - 出力を受け取る側が
true/falseで設計されているか?
2. collectingAndThenの誤用パターンと責務分離の考え方
collectingAndThenは、collectで得られた結果に対して後処理を加えるCollectorです。
その便利さゆえに、「つい色々まとめて書きたくなる」リスクも高く、レビューでは“後処理の妥当性”と“構造の明確性”を見抜く必要があります。
2.1 基本形
Collector<User, ?, List<String>> emails =
Collectors.collectingAndThen(
Collectors.mapping(User::getEmail, Collectors.toList()),
Collections::unmodifiableList
);これは「emailを抜き出し、最後に不変化する」という構造です。
collectingAndThenは“構造の出口での変換”だが、副作用的な用途や別責務を背負わせると破綻しやすい。
2.2 ありがちな“やりすぎ”例
Collectors.collectingAndThen(
Collectors.toList(),
list -> {
auditService.log(list); // 副作用
return list;
}
);このように、副作用処理や外部依存処理を後段に入れる構造は、Collector本来の純粋性を破壊します。
レビュー観点
- collectingAndThenの
then側が純粋関数か?(構造変換に徹しているか?) - 副作用が含まれていないか?
- “Post-processing”の意図が他と混ざっていないか?
3. reducingの活用と他Collectorとの選択判断
Collectors.reducing()は、Stream全体を1つの結果に畳み込む終端操作です。
ただし、map → reduceで済む場合にcollect(reducing(...))を使うと、構造が冗長になりやすく、レビュー時の意図読解コストが上がることがあります。
3.1 基本形
OptionalInt max =
numbers.stream().collect(Collectors.reducing(Integer::max));3.2 明示的な初期値・変換・合成処理
Integer totalLength =
names.stream().collect(Collectors.reducing(
0,
String::length,
Integer::sum
));- 初期値:0
- 変換:String → Integer
- 合成:sum
reducingは「畳み込み」の設計に明確な意図があるときに選ぶべき。
単純な合計ならmapToInt().sum() の方が意図が伝わる。
レビュー観点
- reducingの使用が“構造として必然か?”それとも他の方法(mapToInt().sum()など)の方が読みやすいか?
- 初期値が正しく設定されているか?
- 変換関数と合成関数の分離が適切に書かれているか?
4. 組み合わせCollectorの構造可視性とメンテナンス性
groupingBy + mapping + collectingAndThen のようなCollector合成は、Streamの柔軟性の象徴であると同時に、構造追跡の難所でもあります。
4.1 複雑な合成例
Map<String, Set<String>> result =
users.stream().collect(Collectors.groupingBy(
User::getDepartment,
Collectors.collectingAndThen(
Collectors.mapping(User::getRole, Collectors.toSet()),
Collections::unmodifiableSet
)
));このように3層以上のCollectorが合成されている場合、レビュー観点では以下を精査する必要があります。
合成が深くなると、処理意図とデータ構造の対応関係が不明瞭になり、後から改修・拡張しにくいStream構文になってしまう。
レビュー観点
- 各段階の役割(集約・変換・整形)が分離できているか?
- 最終的に得られるMapやListの型と、開発者が期待している型が一致しているか?
- どの処理が構造変換で、どの処理がビジネス的整形か?
5. Stream出口設計におけるデータ整形 vs 意図抽象化のバランス
Streamの終端では、そのままの構造で出すか、目的に応じて変換するかという判断が求められます。
レビューでは、“処理の出口で何を返しているか”が、その構造で良いのかどうかを見極める視点が必要です。
5.1 整形の例(単なる変換)
users.stream()
.map(User::getName)
.collect(Collectors.toList()); // 単なるデータ抽出5.2 意図の抽象化(構造変換)
Map<String, List<User>> grouped =
users.stream().collect(Collectors.groupingBy(User::getRole));ここでは構造自体に意味が含まれるようになっており、「意図を含んだデータの形」が形成されています。
Stream出口で“構造が残る”設計か、“値のみが残る”設計かによって、責務やユースケースが異なる。
レビュー観点
- 終端で得られるデータの構造は“その後の使い道”に合っているか?
- 単純なListならOKか? それともMapやSetに変換して“意図あるデータ”にすべきか?
6. 構造を読めるCollector設計とレビュー支援の実践ガイド
JavaのCollectorは、そのままでは読みにくい構文になりがちです。
しかしレビューアーがStream構造を読み解けるようにすることで、実装者の意図を補完し、将来の改修や拡張に対応しやすいコード基盤を育てることができます。
ベストプラクティス集
- ネストされたCollectorは必ず中間段階で関数化・命名を検討する
- collectingAndThenの副作用混入を避け、“構造変換”に限定する
- partitioningByはbooleanロジックが明示できる場合に選ぶ
- reducingは集約構造が明確に求められるときのみに使用し、冗長な畳み込みは避ける
「コードの見た目」より「構造の意図」が読めるCollectorを設計すること。
レビューアーは構文ではなく構造を評価すべき。
結論
Stream APIの終端構造は、単なる処理の終わりではなく「データの出口」「意味の顕在化ポイント」です。
Collectorの選択と設計がそのままユースケースやドメイン設計の意図を反映するため、レビューでは“正しく動いているか”ではなく、“正しい形で設計されているか”を見極めることが重要です。
このようにCollectorの設計を“構造設計”として扱えるようになれば、Stream APIはレビューアブルな機能設計言語へと昇華されます。