C++レビュー|検索最適化とアルゴリズム選定責任整理レビュー
この記事のポイント
- 検索処理におけるアルゴリズム選定責任をレビューアー視点で整理
- 線形・二分・ハッシュ各種探索の設計適用条件を具体的に読み解く
- API契約・性能責任・スケーラビリティ設計まで含めたレビュー観点を体系化
そもそも検索最適化とは
検索とは:
- コレクション(配列・リスト・マップ等)内から
- 条件を満たす要素を探し出す処理
だが「どの検索アルゴリズムを選ぶか」は設計責任そのものになる。
| 種類 | 計算量 | 代表アルゴリズム |
|---|---|---|
| 線形探索 | O(N) | find, find_if |
| 二分探索 | O(logN) | lower_bound, binary_search |
| ハッシュ探索 | O(1)平均 | unordered_map, unordered_set |
- 探索性能は設計責任と直結する
- 規模・頻度・前提条件次第で最適解が激変
なぜこれをレビューするのか
レビューアー視点
検索最適化設計は以下の設計責任整理が必要。
-
探索回数責任
→ 繰返し回数と探索方式の整合確認 -
前提条件保証責任
→ ソート済保証、ハッシュ一意保証をAPI契約で整理 -
事前構築コスト責任
→ index/map構築コストと運用コスト整理 -
スケーラビリティ保証責任
→ 件数増大時の漸近特性確認 -
API契約安全性保証
→ 呼出側の利用契約文書化
開発者視点
- find一択思考
- lower_bound適用不慣れ
- unordered_map適用軽視
- 構築コスト評価不在
- 件数規模による適用分岐不在
レビューアーはこれら「探索戦略不在設計」を早期検出する役割を担う。
良い実装例(線形探索)
ユースケース:APIログから特定requestIdの存在確認
#include <vector>
#include <string>
#include <algorithm>
struct ApiRequestLog {
std::string requestId;
};
bool hasRequest(const std::vector<ApiRequestLog>& logs, const std::string& targetId) {
return std::find_if(logs.begin(), logs.end(),
[&targetId](const ApiRequestLog& log) {
return log.requestId == targetId;
}) != logs.end();
}- 件数小規模なら線形探索で十分
- 一過性検索なら構築不要
- 意図表現が簡潔
レビュー観点
- 件数規模が線形探索許容範囲内か
- 検索頻度が高頻度化しないか
- 構築型探索導入余地が本当にないか
- API契約に検索特性が整理されているか
良い実装例(二分探索)
ユースケース:ソート済みAPIログから範囲抽出
#include <vector>
#include <algorithm>
#include <cstdint>
struct ApiRequestLog {
int64_t requestedAt;
};
std::vector<ApiRequestLog> findRange(const std::vector<ApiRequestLog>& logs, int64_t from, int64_t to) {
auto comp = [](const ApiRequestLog& log, int64_t val) {
return log.requestedAt < val;
};
auto lower = std::lower_bound(logs.begin(), logs.end(), from, comp);
auto upper = std::upper_bound(logs.begin(), logs.end(), to, comp);
return std::vector<ApiRequestLog>(lower, upper);
}- 事前ソート保証で高速化
- 二分探索でO(logN)性能確保
レビュー観点
- ソート保証契約がAPI内で責任整理されているか
- 比較関数のstrict weak ordering順守確認
- lower_bound/upper_boundの境界条件妥当性確認
良い実装例(ハッシュ探索)
ユースケース:リクエストIDの存在管理
#include <unordered_set>
#include <string>
class RequestRegistry {
public:
void registerId(const std::string& id) {
ids_.insert(id);
}
bool exists(const std::string& id) const {
return ids_.find(id) != ids_.end();
}
private:
std::unordered_set<std::string> ids_;
};- O(1)探索保証
- 登録頻度と照合頻度が高い設計に有効
レビュー観点
- 一意性契約責任が設計で整理されているか
- rehash発生時の性能安定化設計がなされているか
- reserveバケット設計が契約化されているか
良くない実装例: ケース1
以下は件数多量でも線形探索一択で性能悪化する例。
bool exists(const std::vector<ApiRequestLog>& logs, const std::string& targetId) {
for (const auto& log : logs) {
if (log.requestId == targetId) {
return true;
}
}
return false;
}
@Reviewer件数規模次第でunordered_set導入による探索最適化が検討可能です。
問題点
- 件数増加でO(N)性能劣化
- 高頻度用途で負荷膨張
改善例
std::unordered_set<std::string> ids;
ids.insert(...);
ids.find(targetId) != ids.end();良くない実装例: ケース2
次はlower_bound利用前提でソート保証責任放置している例。
auto it = std::lower_bound(logs.begin(), logs.end(), from,
[](const ApiRequestLog& log, int64_t val) {
return log.requestedAt < val;
});
@Reviewerlower_bound前提には事前ソート保証責任が伴います。API設計でソート契約を明文化してください。
問題点
- ソート保証が呼出側責任に委譲
- 誤動作原因が設計不明化
改善例
prepareSort();
lower_bound使用開始良くない実装例: ケース3
次はunordered_mapでreserve適用を怠りrehash負荷発生する例。
std::unordered_set<std::string> ids;
for (const auto& id : source) {
ids.insert(id);
}
@Reviewer大量登録時はreserveでバケット事前確保を設計してください。
問題点
- 再確保負荷膨張
- 高負荷時の性能安定性劣化
改善例
ids.reserve(expectedSize);検索アルゴリズム選定早見表
| 条件 | 推奨探索法 |
|---|---|
| 件数極少 | find / find_if |
| 件数多 + 一過性 | lower_bound(事前ソート) |
| 件数多 + 頻繁照合 | unordered_set / unordered_map |
| 範囲抽出 | lower_bound / upper_bound |
| インデックス型最適化 | map/set(順序保証必要時) |
検索戦略設計責任整理
API契約に責務整理を埋め込む
bool hasRequest(const std::string& id); // → 線形orハッシュはAPI内部責務
void prepareIndex(); // → 呼出側に構築責任移譲可能パフォーマンス責任をレビュー時明文化
- 規模閾値(例:1000件超えたら構築型へ)
- 初期確保容量設計
- 再構成設計有無
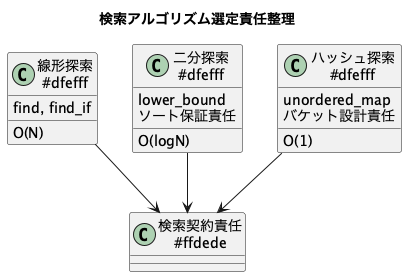
PlantUMLで検索設計責任整理
観点チェックリスト
実務レビューFAQ
Q1. 件数100件程度でもunordered_map必要?
→ 線形で十分。頻度・件数・寿命次第で判断。
Q2. lower_boundは万能?
→ ソート保証を設計責任で担保できる場合にのみ適用。
Q3. unordered_mapは常に高速?
→ rehash・負荷係数次第。reserve設計が安定化の鍵。
Q4. 検索APIはどこまで内部化すべき?
→ 状態保持責任設計とセットでレビューで分離整理。
Q5. 動的閾値切替設計は実務で使う?
→ 大規模処理では線形→ハッシュ切替戦略を持つ設計が現場で有効。
まとめ
検索最適化とアルゴリズム選定は設計責任の縮図である。
レビューアーは
- 件数規模責任
- 前提保証責任
- 構築責任
- スケーラビリティ責任
を読み解き、検索APIは契約設計が支配するという視点でレビューを進める必要がある。
レビューアーが検索設計責任を整理できるとAPI設計品質が格段に上がる。