C++レビュー|algorithmヘッダの標準アルゴリズム利用推奨と設計レビュー責任整理
この記事のポイント
- algorithmヘッダ活用をレビューアー視点で設計責任整理
- 標準アルゴリズム利用が意図表現・安全性・保守性を高める理由を理解
- ループ→algorithm化レビューを実践で読み取る力を養う
そもそもalgorithmヘッダとは
C++標準ライブラリのalgorithmヘッダは汎用アルゴリズム群を提供する。
- sort, find, copy, transform, accumulate など汎用的操作
- イテレータ範囲を対象に動作
- 抽象化の役割:操作の意図を直接表現
#include <algorithm>
std::sort(vec.begin(), vec.end());- 冗長ループ排除の基本武器
- 抽象度を上げた意図表現
- 失敗しづらい安全性強化
なぜこれをレビューするのか
レビューアー視点
algorithm活用は以下の設計責務整理を伴う。
-
「何をするのか」を明文化する責務
→ 単なる「どうするのか」記述からの脱却 -
ループ内誤動作・境界ミス排除
→ off-by-one、size取得誤りの予防 -
API契約と操作責任の明文化
→ 標準API責任分離による再利用性確保 -
例外安全・リソース確保責任整理
→ algorithm使用時に例外発生経路を限定可能 -
スケーラビリティ設計の安定化
開発者視点
- ついfor文を書きがち
- 関数利用に不慣れ
- 自前ループ癖が抜けない
- アルゴリズム特性・複雑度を意識しない
- 意図が読みづらい手続き的コードを書く
レビューアーはこれら「ループ依存思考」から抜け出す支援を行う。
良い実装例
ユースケース:APIレスポンスログの成功件数カウント
#include <algorithm>
#include <vector>
#include <string>
#include <cstdint>
struct ApiRequestLog {
std::string requestId;
int responseCode;
int64_t requestedAt;
};
class RequestLogAnalyzer {
public:
int countSuccess(const std::vector<ApiRequestLog>& logs) const {
return std::count_if(logs.begin(), logs.end(),
[](const ApiRequestLog& log) {
return log.responseCode >= 200 && log.responseCode < 300;
});
}
};- forループ消滅
- 意図=条件判定がコードの中心に
- 安全性・可読性向上
レビュー観点
- 明文化された「何をするコードなのか」へ整理できているか
- ループ→algorithm置換余地が残っていないか
- 境界誤差・サイズ誤差をレビュー時に事前排除できているか
- API契約が高抽象設計に整理されているか
良くない実装例: ケース1
以下は自前for文でループを直接書いてしまった例。
int countSuccess(const std::vector<ApiRequestLog>& logs) const {
int count = 0;
for (size_t i = 0; i < logs.size(); ++i) {
if (logs[i].responseCode >= 200 && logs[i].responseCode < 300) {
++count;
}
}
return count;
}
@Reviewer意図が「成功件数を数えたい」である以上、count_if利用で明文化可能です。
問題点
- 目的が読み取れない
- 境界条件やsize誤用リスク
- 手続き的表現
改善例
return std::count_if(...);良くない実装例: ケース2
次はremove_ifの存在を知らず全件ループしてeraseを多発している例。
void removeServerError(std::vector<ApiRequestLog>& logs) {
for (auto it = logs.begin(); it != logs.end(); ) {
if (it->responseCode >= 500) {
it = logs.erase(it);
} else {
++it;
}
}
}
@Reviewerremove-eraseイディオム利用で一括処理が可能です。
問題点
- erase呼出負荷が高まる
- iterator失効管理負荷増加
改善例
logs.erase(std::remove_if(logs.begin(), logs.end(),
[](const ApiRequestLog& log) {
return log.responseCode >= 500;
}), logs.end());- remove_ifは「残したいものを前詰め」る操作
- eraseは範囲指定で一気に破壊
良くない実装例: ケース3
次はtransform(map的変換)が適用できる場面でfor文を維持してしまった例。
std::vector<int> extractCodes(const std::vector<ApiRequestLog>& logs) const {
std::vector<int> codes;
for (const auto& log : logs) {
codes.push_back(log.responseCode);
}
return codes;
}
@Reviewertransformを利用すれば変換意図が明文化できます。
問題点
- 目的「レスポンスコード抽出」が埋没
- push_back安全性責任を自前保持
改善例
std::vector<int> codes(logs.size());
std::transform(logs.begin(), logs.end(), codes.begin(),
[](const ApiRequestLog& log) { return log.responseCode; });- 出力先事前確保責任は呼出側に残る
algorithm設計責任を活かすAPI契約整理
パターンA:単純条件計数系
int countValidRequests(const std::vector<ApiRequestLog>& logs);- count_if契約
- 境界バグ可能性低下
パターンB:条件削除系
void filterOutInvalid(std::vector<ApiRequestLog>& logs);- remove-erase契約
- 破壊責任明文化
パターンC:要素変換系
std::vector<int> extractResponseCodes(const std::vector<ApiRequestLog>& logs);- transform契約
- 抽出意図を型レベルに昇格
algorithm活用レビューでよくある誤解
| 誤解 | 正しい設計観点 |
|---|---|
| forの方がわかりやすい | 意図が埋没しやすい |
| algorithmは特殊用途 | 汎用操作である |
| ループの方が柔軟 | 柔軟さより責任整理優先 |
| 境界はsize()管理できる | off-by-one誘発源 |
| algorithmは初心者向け | 設計上級者の責任整理道具 |
algorithm主要カテゴリ整理
| 分類 | 主な関数 | レビューで使う観点 |
|---|---|---|
| 検索 | find, find_if | 条件一致責任整理 |
| 計数 | count, count_if | 状態件数契約 |
| 削除 | remove, remove_if | 破壊責任整理 |
| 変換 | transform | 要素変換責任整理 |
| 並べ替え | sort, stable_sort | 並び順保証契約 |
| 集約 | accumulate | 総和・集約責任整理 |
- algorithm活用レビューは「操作→契約昇格」レビュー
PlantUMLで設計責任整理
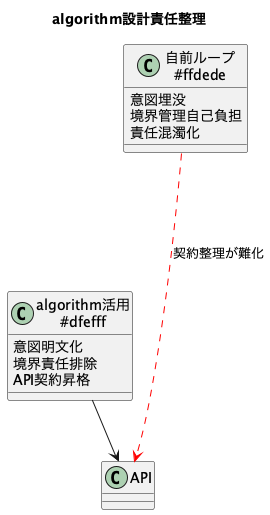
観点チェックリスト
実務レビューFAQ
Q1. for文が一番高速では?
→ 近年の標準algorithmは最適化込み。可読性・責任分離を優先。
Q2. algorithmは学習コスト高い?
→ 実は範囲設計に慣れるだけ。責任整理が早期に学べる。
Q3. remove_ifは削除してない?
→ remove_ifは後詰め操作、eraseで破壊責任完了。
Q4. transformは積極採用すべき?
→ map的変換には必須級。transform癖をつけると可読性上がる。
Q5. algorithmは例外安全?
→ 境界安全を内包。例外安全性向上に繋がる設計要素。
まとめ
algorithmヘッダは手続き的ループ設計からの脱却装置である。
レビューアーは
- 目的の意図を読み取る
- ループ→algorithm変換可能性を見抜く
- API契約責任まで昇格提案できる
この思考技術を磨く必要がある。
レビューアーがalgorithmを語れると設計品質が劇的に上がる。