C++レビュー|insert・erase操作の計算量と設計レビュー観点の整理
この記事のポイント
- insert・erase操作の計算量をコンテナ別に整理
- コンテナ選定理由の設計意図をレビューアー視点で読み解く
- 性能ではなく設計責務としてのinsert/erase選択を意識する技術を学ぶ
そもそもinsert・eraseの計算量とは
C++標準ライブラリのコンテナは、目的によって計算量特性が大きく異なるよう設計されています。
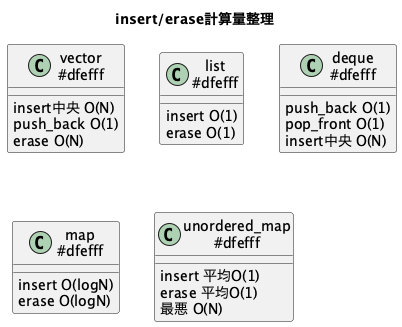
以下は主要コンテナにおけるinsert・eraseの一般的な計算量整理です。
| コンテナ | insert | erase | 備考 |
|---|---|---|---|
| vector | O(N)(中央挿入) O(1)(末尾push_back) |
O(N) | 末尾操作に特化 |
| deque | O(N)(中央) O(1)(先頭・末尾) |
O(N) | 両端操作向き |
| list | O(1)(イテレータ位置指定) | O(1)(イテレータ位置指定) | 双方向リスト |
| set/map | O(log N) | O(log N) | 平衡二分探索木 |
| unordered_set/map | 平均O(1) 最悪O(N) |
平均O(1) 最悪O(N) |
ハッシュ表 |
| priority_queue | O(log N)(push/pop) | - | pop以外のerase不可 |
計算量は使用パターン次第で全く意味が変わる。
レビューアーは必ず「どこで・何件・どの位置に」挿入/削除されるかまで確認すること。
なぜこれをレビューするのか
レビューアー視点
insert/eraseの性能は以下のように設計責任と密接に関わります。
-
中央挿入の想定有無
→ vector中央挿入多発 → list検討必要 -
削除頻度
→ erase使用時の計算量理解 -
事前計算可能件数
→ reserveの使用有無 -
ユースケース拡大時のスケーラビリティ保証
-
並列化・非同期化への適合性
開発者視点
- ついvectorを万能視して中央insert多用
- eraseを繰り返し呼び出して性能劣化に気付かない
- mapのeraseはO(1)だと誤解
- unordered_mapの最悪O(N)を認識しない
レビューではこれらの「計算量忘却設計」を補正する役割を担います。
良い実装例
ユースケース:APIリクエストバッファ(末尾追加・先頭削除のみ)
良い実装例:deque活用
#include <deque>
#include <string>
#include <cstdint>
struct ApiRequestLog {
std::string requestId;
int responseCode;
int64_t requestedAt;
};
class RequestBuffer {
public:
void addRequest(const ApiRequestLog& log) {
buffer_.push_back(log);
}
void removeOldest() {
if (!buffer_.empty()) {
buffer_.pop_front();
}
}
private:
std::deque<ApiRequestLog> buffer_;
};- 末尾追加O(1)、先頭削除O(1)が両立
- vectorでは中央シフト発生 → O(N)
- listよりメモリ局所性優位
レビュー観点
- 中央挿入/削除が発生する可能性はあるか
- erase使用頻度が想定より高くないか
- reserve活用有無(vector限定)
- イテレータ無効化への配慮
- 最悪計算量評価がレビュー時に示されているか
良くない実装例: ケース1
以下はvector中央挿入を多用してしまったケースです。
vector中央挿入誤用例
#include <vector>
#include <string>
#include <cstdint>
struct ApiRequestLog {
std::string requestId;
int responseCode;
int64_t requestedAt;
};
class RequestLogInserter {
public:
void insertAt(const ApiRequestLog& log, size_t index) {
if (index <= logs_.size()) {
logs_.insert(logs_.begin() + index, log);
}
}
private:
std::vector<ApiRequestLog> logs_;
};
@Reviewervectorは中央挿入がO(N)コストです。挿入頻度次第ではlistまたはdequeを検討してください。
問題点
- insert(begin() + index)は都度全体シフト
- 頻繁に呼ばれるなら実行時間が線形肥大
改善例
修正例:list活用による中央挿入最適化
#include <list>
class RequestLogInserter {
public:
void insertAt(const ApiRequestLog& log, std::list<ApiRequestLog>::iterator pos) {
logs_.insert(pos, log);
}
auto begin() { return logs_.begin(); }
auto end() { return logs_.end(); }
private:
std::list<ApiRequestLog> logs_;
};- イテレータ位置指定により中央挿入O(1)
- 全件ソート処理が不要なら有利
- listのメモリ分散コストは用途次第
良くない実装例: ケース2
次はunordered_mapのerase計算量を誤解している例です。
unordered_map erase誤用例
#include <unordered_map>
#include <string>
#include <cstdint>
struct ApiRequestLog {
std::string requestId;
int responseCode;
int64_t requestedAt;
};
class RequestIndex {
public:
void add(const ApiRequestLog& log) {
index_[log.requestId] = log;
}
void remove(const std::string& id) {
index_.erase(id);
}
private:
std::unordered_map<std::string, ApiRequestLog> index_;
};
@Reviewereraseは平均O(1)ですが最悪O(N)も発生します。高負荷時の衝突率評価が必要です。
問題点
- unordered_mapのeraseは衝突管理依存
- キー分布次第で最悪O(N)もあり得る
改善例
修正例:リハッシュ戦略を併用
void prepare(size_t expectedSize) {
index_.reserve(expectedSize);
}- reserveによりバケット初期容量確保
- 衝突発生を事前緩和
- 設計時にexpectedSize予測が有効
PlantUMLで計算量整理
観点チェックリスト
まとめ
insert・eraseの計算量設計は、「操作回数×コスト」の積で実行性能を決定付ける重要要素です。
レビューアーは単純な計算量表暗記ではなく、
- 操作位置
- 操作頻度
- データ規模
- 最悪ケース発生可能性
これら4軸の交差点を読み解くことが求められます。
レビューで構造そのものを疑う癖を養うと、設計全体の安定性が大きく向上します。