C++レビュー|priority_queueの用途整理と設計レビュー観点の体系化
この記事のポイント
- C++におけるpriority_queueの構造と設計意図をレビューアー視点で整理
- 適切な用途・適さない用途を明確に把握する
- 比較関数・ヒープ構造・アルゴリズム的責任範囲をレビューする技術を学べる
そもそもpriority_queueとは
C++標準ライブラリにおけるpriority_queueは、ヒープ構造(通常は二分ヒープ)を内部に採用した優先度付きキューです。
常に最大(または最小)の要素を高速に取り出せる構造になっています。
- 内部構造
- デフォルトは
std::vector上の二分ヒープ(std::make_heap等と同等)
- デフォルトは
- 基本操作性能
- 挿入:O(log N)
- 取り出し:O(log N)
- 最大値参照:O(1)
- 並び順
- 比較関数で定義(
std::lessがデフォルト)
- 比較関数で定義(
priority_queueの本質
- キューでもソートでもない
- ヒープという局所的ソート保証
- 全体順序は保証されない
なぜこれをレビューするのか
レビューアー視点
priority_queueは「並べたいなら使えばいい」と誤解されがちです。
レビューでは以下の論点整理が重要です。
-
優先度定義責任の明確化
→ 比較関数が設計に適合しているか -
全体順序保証と誤解していないか
→ 要素全走査用途に流用していないか -
データ件数規模に対する性能見積もり
→ 過大負荷時の動作確認有無 -
使い捨てor長期維持構造か
→ リアルタイム処理と一括処理でアプローチが異なる -
ソートではなく逐次最適化が目的か
→ 常に「今最良」を求める設計意図確認
開発者視点
- ソートの代わりにpriority_queueを使う
- 比較関数の設計責任を持たない
- デバッグ出力用に全要素取り出し → 再構成コスト無視
- ソート順とキュー順を混同する
- priority_queueに安易にcopyして並び順確認 → 実質O(NlogN)
レビューではこれらの認識齟齬を防止します。
良い実装例
ユースケース:APIリクエストの処理優先度管理(高負荷時の優先消化)
良い実装例:priority_queueの逐次優先制御
#include <queue>
#include <string>
#include <cstdint>
struct ApiRequestLog {
std::string requestId;
int priority; // 優先度:値が大きいほど高優先
int64_t requestedAt;
};
// 優先度降順ソート用比較関数
struct ComparePriority {
bool operator()(const ApiRequestLog& a, const ApiRequestLog& b) const {
return a.priority < b.priority; // 値大きい方が優先
}
};
class RequestProcessor {
public:
void addRequest(const ApiRequestLog& log) {
queue_.push(log);
}
bool hasPending() const {
return !queue_.empty();
}
ApiRequestLog nextRequest() {
auto top = queue_.top();
queue_.pop();
return top;
}
private:
std::priority_queue<ApiRequestLog, std::vector<ApiRequestLog>, ComparePriority> queue_;
};- 毎回トップの優先度最大要素を即時処理できる
- 比較関数は設計責任の明示となる
- 全体順序には依存しない
レビュー観点
- 優先度設計はドメイン要求に紐づいているか
- 比較関数の定義責任が明文化されているか
- queue操作前後でヒープ破壊されない実装になっているか
- データ規模拡大時の性能見積もりはあるか
- 「全体順序を得るために使っていないか」を確認
良くない実装例: ケース1
以下は全体ソート目的でpriority_queueを使ってしまった例です。
誤用例:全件並べたい
#include <queue>
#include <vector>
#include <string>
#include <cstdint>
struct ApiRequestLog {
std::string requestId;
int priority;
int64_t requestedAt;
};
struct ComparePriority {
bool operator()(const ApiRequestLog& a, const ApiRequestLog& b) const {
return a.priority < b.priority;
}
};
class RequestLogSorter {
public:
void sortLogs(std::vector<ApiRequestLog>& logs) {
std::priority_queue<ApiRequestLog, std::vector<ApiRequestLog>, ComparePriority> queue(
logs.begin(), logs.end()
);
logs.clear();
while (!queue.empty()) {
logs.push_back(queue.top());
queue.pop();
}
}
};
@Reviewer全体並べ替え用途ならpriority_queueよりstd::sortを利用してください。priority_queueは逐次最大要素抽出用です。
問題点
- priority_queueは全件並べ替えには向かない
- 結果は安定ソート保証無し
- std::sortならO(NlogN)で一発処理可能
改善例
修正例:通常ソート利用
#include <algorithm>
void sortLogs(std::vector<ApiRequestLog>& logs) {
std::sort(logs.begin(), logs.end(), [](const ApiRequestLog& a, const ApiRequestLog& b) {
return a.priority > b.priority;
});
}- 全件順序目的ではソートを選択
- priority_queueは「常に最大を今すぐ知りたい」用途限定
良くない実装例: ケース2
次は比較関数の定義ミスで優先順位逆転するケースです。
比較関数誤用例
struct ComparePriority {
bool operator()(const ApiRequestLog& a, const ApiRequestLog& b) const {
return a.priority > b.priority;
}
};
@Reviewer比較方向が逆転しています。priority_queueは比較関数がtrueなら順序交換する設計です。
問題点
- priority_queueの比較関数はソートアルゴリズム設計と逆方向定義
- 小さい方が優先に誤って定義されやすい
改善例
修正例:大きい方が優先
struct ComparePriority {
bool operator()(const ApiRequestLog& a, const ApiRequestLog& b) const {
return a.priority < b.priority;
}
};PlantUMLで用途整理
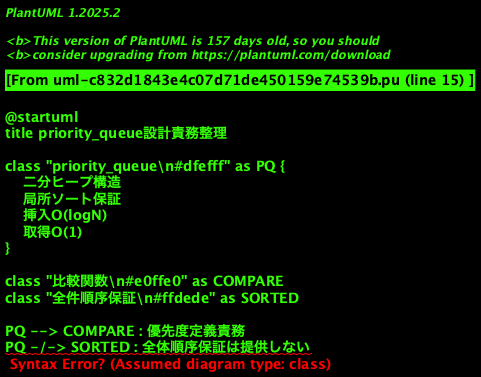
観点チェックリスト
まとめ
priority_queueは逐次的な優先順位抽出を目的とする強力な構造です。
レビューアーは以下の2軸を見誤らないことが肝要です。
- ソートではなく局所最大抽出器であること
- 比較関数責務が「設計そのもの」であること
誤用が頻発する構造だけに、レビューアーの役割は大きくなります。
コード表面ではなく設計意図まで読み解くレビューを常に意識しましょう。