C++レビュー|vectorとlistの選定基準と設計レビュー観点の整理
この記事のポイント
- C++における標準コンテナ選定の根拠をレビューアー視点で説明
- vector・list・dequeを選ぶ際の実務的な基準を整理
- データ規模・更新頻度・キャッシュ性能など多角的な観点を学べる
そもそもコンテナ選定とは
C++では標準ライブラリ(STL)が多様なコンテナを提供しています。vector、list、dequeなどはその代表格です。
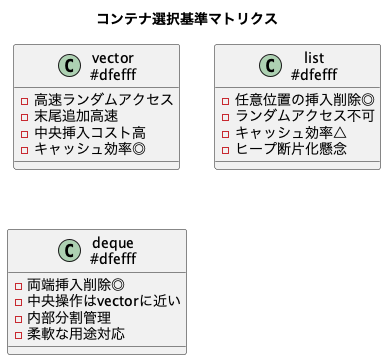
- vector: 連続領域。高速なランダムアクセスと末尾追加性能が特長
- list: 双方向リンクリスト。要素の挿入削除に強いがランダムアクセスに弱い
- deque: 両端キュー。vectorとlistの中間的特性を持つ
コンテナ選定は単なる好みや慣習で行うべきではありません。データ構造の選択は、計算量・CPUキャッシュヒット率・予測されるユースケースに直接影響を与えます。
レビューアーは、選定の根拠を設計意図として読み解くことが重要です。
なぜこれをレビューするのか
レビューアー視点
-
将来のデータ規模を想定した上で選定されているか
数百件ならvector、数百万件ならlistという単純な話ではない。キャッシュフレンドリ性やアルゴリズム特性を踏まえているか。 -
更新頻度・位置を考慮しているか
中央挿入が多発する処理ならlist、末尾追記だけならvector、先頭操作が多ければdequeが候補になる。 -
アルゴリズムとの整合性を取っているか
sort、search、merge等の利用を前提とした設計か。 -
パフォーマンスではなく「設計責務」で整理されているか
配列操作を隠蔽したドメインクラスが提供されているか。
開発者視点
開発者はつい以下のように短絡的に選びがちです。
- とりあえずvector
- listを使えばinsertが速いらしい
- dequeは知らないから使わない
こういった短絡選択を避けるため、開発者自身もコンテナ選定のロジックを持ち、コードにその意図が滲む設計が理想です。
良い実装例
以下はApiRequestLogのバッチ登録処理を想定した実装例です。ユースケースは「リクエストログを時系列順に格納し、バッチで後続処理に渡す」ものです。
#include <vector>
#include <string>
#include <cstdint>
// ログ1件を表すドメイン
struct ApiRequestLog {
std::string requestId;
std::string endpoint;
std::string clientIp;
int responseCode;
int64_t requestedAt;
};
// ログバッファ管理クラス
class RequestLogBuffer {
public:
void add(const ApiRequestLog& log) {
buffer_.push_back(log);
}
const std::vector<ApiRequestLog>& getAll() const {
return buffer_;
}
void clear() {
buffer_.clear();
}
private:
std::vector<ApiRequestLog> buffer_;
};このコードでは、
- 常に末尾追加のみ →
vectorのpush_backが高速 - 読み出し時は全件走査 → 連続メモリによるキャッシュ効率が良い
- 頻繁な挿入削除や中央挿入が発生しない
というユースケースに対して、適切にvectorを選択しています。
レビュー観点
レビューでは以下の観点が重要です。
- 連続メモリが欲しい理由はあるか?(例:キャッシュ効率)
- 中央付近の挿入削除は発生するか?
- データ規模はどの程度か?
- 全件ソート・検索を前提としているか?
- 先頭挿入が必要ならdequeを検討しているか?
- コンテナの選定理由がドキュメント・コメントに残されているか?
良くない実装例: ケース1
以下は典型的に「listを何となく選んでしまった」ケースです。
#include <list>
#include <string>
#include <cstdint>
struct ApiRequestLog {
std::string requestId;
std::string endpoint;
std::string clientIp;
int responseCode;
int64_t requestedAt;
};
class RequestLogBuffer {
public:
void add(const ApiRequestLog& log) {
buffer_.push_back(log);
}
const std::list<ApiRequestLog>& getAll() const {
return buffer_;
}
void clear() {
buffer_.clear();
}
private:
std::list<ApiRequestLog> buffer_;
};
@Reviewerデータは時系列に追加されるだけの用途です。listではなくvectorの方がメモリ局所性が高く、実行時性能も安定します。vectorへの変更を検討してください。
問題点
- 常に末尾追加のみならlistの利点は皆無
- listはランダムアクセス不可
- メモリ分散によるキャッシュミス多発
- listのノード分割によるヒープ断片化
改善例
#include <vector>
#include <string>
#include <cstdint>
struct ApiRequestLog {
std::string requestId;
std::string endpoint;
std::string clientIp;
int responseCode;
int64_t requestedAt;
};
class RequestLogBuffer {
public:
void add(const ApiRequestLog& log) {
buffer_.push_back(log);
}
const std::vector<ApiRequestLog>& getAll() const {
return buffer_;
}
void clear() {
buffer_.clear();
}
private:
std::vector<ApiRequestLog> buffer_;
};- 挿入は常に末尾固定
- キャッシュ効率(局所性)が高い
- データ走査性能が安定
- listに比べメモリアロケーションが大幅に減少
良くない実装例: ケース2
次は「先頭挿入があるのにvectorを選んでしまった」例です。
#include <vector>
#include <string>
#include <cstdint>
struct ApiRequestLog {
std::string requestId;
std::string endpoint;
std::string clientIp;
int responseCode;
int64_t requestedAt;
};
class RequestLogBuffer {
public:
void addToFront(const ApiRequestLog& log) {
buffer_.insert(buffer_.begin(), log);
}
const std::vector<ApiRequestLog>& getAll() const {
return buffer_;
}
void clear() {
buffer_.clear();
}
private:
std::vector<ApiRequestLog> buffer_;
};
@Reviewer先頭挿入が頻繁に発生するならdequeの方が適しています。vectorはinsert(begin())がO(N)でコスト高です。
問題点
- 先頭挿入は毎回全要素シフトが必要
- 頻度次第で性能劣化が著しい
- 意図的にvectorを使うなら理由説明が必要
改善例
#include <deque>
#include <string>
#include <cstdint>
struct ApiRequestLog {
std::string requestId;
std::string endpoint;
std::string clientIp;
int responseCode;
int64_t requestedAt;
};
class RequestLogBuffer {
public:
void addToFront(const ApiRequestLog& log) {
buffer_.push_front(log);
}
const std::deque<ApiRequestLog>& getAll() const {
return buffer_;
}
void clear() {
buffer_.clear();
}
private:
std::deque<ApiRequestLog> buffer_;
};- 先頭・末尾の両方に高速な追加削除
- 内部は分割連続領域の管理
- 完全な連続メモリではないがvectorより柔軟性
PlantUMLによる用途整理
観点チェックリスト
まとめ
コンテナ選定は、目先のコーディング効率ではなく、設計意図を反映する重要な設計判断です。
レビューアーは、データ流通量・操作頻度・API提供意図・パフォーマンス特性を複合的に読み解き、開発者の選択理由を確認する役割を持ちます。
今回のvector、list、dequeの整理は、その基礎となる設計思考の一例です。
今後のレビューではぜひ「なぜこのコンテナ?」を常に意識してみてください。