C++17 fatal/terminate動作設計レビュー|致命的障害の終了方針とレビューアーが確認すべき設計一貫性
この記事のポイント
- fatal/terminate動作設計のレビュー観点を整理
- 致命的障害の終了戦略を設計責務分界としてレビューできる
- 「どの障害がプロセス終了に直結するべきか?」をレビューアーが設計判断する力を身につける
そもそもfatal/terminate動作とは何か
C++における異常系終了は、大きく次の流れで発生します。
| 発生形態 | 例 | 終了制御 |
|---|---|---|
| 明示的 | std::terminate()、abort() |
プログラム即時強制終了 |
| 間接的 | noexcept違反、スタック枯渇 |
terminate発動 |
| OS連携 | セグフォ、アクセス違反 | シグナル発動によるkill |
レビューアーは「設計上ここでterminateしてよいのか?」を判断すべきです。
なぜこれをレビューするのか
- fatal/terminate動作はユーザ影響・運用影響が極めて大きい
- 設計層が無自覚に異常終了条件を埋め込むことが多い
- 異常終了設計の責任分界を設計初期に固定化すべき
レビューでは致命的障害の発火条件と終了方針が一貫しているかを精査する。
レビューアー視点
- この障害はプロセス終了が適切か?
- 異常終了ポリシーがプロジェクト内で統一されているか?
- noexcept設計とterminateポリシーが整合しているか?
- OS信号系と例外系が混在破綻していないか?
- 復旧不能な定義が曖昧になっていないか?
開発者視点
- 原則「復旧不能・設計破綻のみ終了対象」
- ユーザ入力不正・外部障害はrecoverable系で処理
- fatal条件はトップレベル設計で明示固定
- ログ設計と終了ポリシーは常に統合管理
良い設計例
設計破綻=terminate許容
契約破綻による強制終了
void critical() noexcept {
throw std::runtime_error("forbidden failure"); // noexcept違反 → terminate
}- noexcept契約に違反する設計破綻はterminate
- 本質的にrecoverableでないため正当化可能
明示terminate設計
異常終了ポリシー統合
#include <exception>
void unrecoverable() {
std::terminate();
}- 設計時点で統一的にfatal条件管理
レビュー観点
- terminate条件が設計定義されているか
- noexcept適用範囲が過剰・不足でないか
- recoverable障害がterminate条件に混入していないか
- シグナル系障害と例外系障害が設計上整理されているか
- fatal発生前にログ・監視通知が確実に出力されているか
良くない実装例: ケース1(過剰noexcept)
noexcept濫用による終了拡大
class Service {
public:
void process() noexcept {
repository.save();
@Reviewerrepository.save()は例外可能性があります。noexcept適用は危険です。契約整合性を確認してください。 }
};改善例
改善例(契約調整)
class Service {
public:
void process() {
repository.save();
}
};良くない実装例: ケース2(ユーザ入力がfatal昇格)
入力不正を即終了扱い
void validateUser(int id) {
if (id <= 0) {
std::terminate();
@Reviewer入力検証失敗はrecoverable障害です。例外通知に設計統一してください。terminate対象ではありません。 }
}改善例
改善例(例外系移行)
void validateUser(int id) {
if (id <= 0) {
throw std::invalid_argument("invalid user id");
}
}良くない実装例: ケース3(異常終了ポリシー不統一)
層毎に終了方式がバラバラ
void service() {
repository.save();
std::terminate(); // ここで即終了
@Reviewer層毎に異常終了方針が分断しています。全体の統一終了ポリシーに従ってください。}改善例
改善例(統合終了ポリシー)
try {
service();
} catch (const std::exception& e) {
logger.fatal("Fatal error: {}", e.what());
std::terminate();
}- 終了責務はトップレベルに統一配置
PlantUML:fatalポリシー責務流れ図
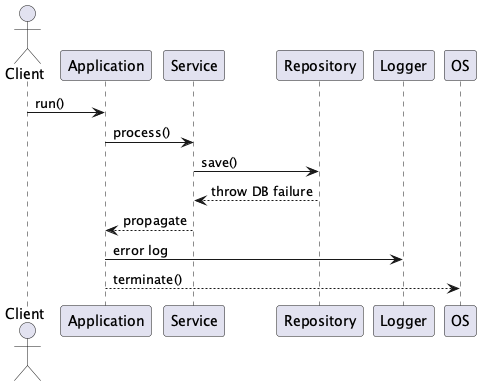
ロギング統合例
fatal前の統合ログ出力
try {
app.run();
} catch (const std::exception& e) {
logger.fatal("Application terminated: {}", e.what());
notifyFatal(e);
std::terminate();
}- 異常終了の前に必ず診断可能な情報を残す
観点チェックリスト
まとめ
レビューアーがfatal/terminate設計で常に問うべきは
「この障害はプロセスを終了すべき設計責務か?」
です。
- recoverable系は例外通知へ整理
- 設計破綻系のみterminate統一管理
- fatal前は確実に障害情報を記録出力
fatal設計はレビューアーが現場影響・運用影響を理解した上で設計者に質問を投げる力が求められます。