AIレビューを組み込んだCI/CDフローの設計例と課題
はじめに
AIによるコードレビュー機能が実用段階に入りつつある中で、CI/CDパイプラインにAIレビューを組み込む構成が現実味を帯びてきた。
ただし、従来の静的解析とは異なる自然言語ベースのAI出力をどのようにCIの中に統合し、レビュープロセス全体の信頼性を担保するかは、レビューアーにとって極めて重要な設計課題である。
本記事では、AIレビューのCI/CD組み込みに向けた実践的なフロー設計例を提示し、レビューアーの立場からのチェック観点、技術的・運用的課題を整理していく。
背景:AIレビューの位置づけ
近年、GitHub CopilotやCodeWhispererのような生成支援AIに加え、CodiumAIやCodeRabbitといったレビュー特化型LLMの導入が進んでいる。
これらは静的解析ツールとは異なり、文脈・意味・意図を解釈しながらコメントを生成できるが、形式的なエラー検出よりも提案的なアウトプットに寄る傾向が強い。
そのため、レビューアーは以下の点を理解しておく必要がある:
- コメントの妥当性は確率的な推論に基づいており、精度にはばらつきがある
- コメントには論理的根拠の省略がある場合も多く、読み手が補完する必要がある
- 誤検知・漏検知のリスクを想定した上で補完的ツールとして扱うのが基本
AIレビューとは、自然言語処理技術(LLMなど)を用いて、ソースコードの構造・ロジック・スタイルに対する自動的なレビューコメントを生成する仕組み。
従来のLinterや型チェッカーと異なり、自然言語でのフィードバックや設計意図の読み取りが可能とされる。
組み込み設計:CI/CDフローへの配置例
まず、CI/CDパイプラインにおいてAIレビューをどこに配置するかを定義する必要がある。以下にその代表的な構成を示す。
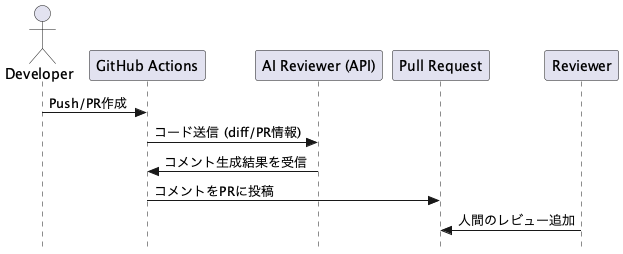
この構成のポイントは以下の通り:
- PR作成時にCIがAIレビューを自動で呼び出し
- AIコメントはPRスレッドに投稿され、後続のレビュー作業の参考にされる
- 人間のレビューを代替せず補助とする位置づけ
実装上の考慮点
実際にCI/CDでAIレビューを動かす際には、以下のような実装課題がある。
1. 入力データの適切な整形
LLMベースのAIは入力の形式に敏感であり、以下のような情報が求められる:
- PRのdiffだけでなく前後の文脈
- ファイル単位ではなく関数単位・責務単位での切り出し
- インラインコメント可能な粒度での分割と整形
2. 出力の構造化
AIコメントの多くは自然文で返されるため、そのままCIで使用するには以下の処理が必要:
- ファイル名・行番号付きのメタ情報抽出
- コメントの分類(バグ指摘・リファクタ提案など)
- 過剰なコメントや重複指摘のフィルタリング
@Reviewer: 同一関数内に対して冗長なコメントが複数生成されている場合、重複を排除し要約する前処理を挟む必要がある。3. トークン数制限と分割戦略
大規模LLMはトークン制限があるため、大きなdiffやファイルに対してはスライディングウィンドウ戦略や要約→詳細戦略を組み合わせる。
レビューアー視点の設計課題
レビューアーがチェックすべき観点は以下である:
- 人間のコメントとの役割分担:AIがコメントした範囲に人間が再レビューすべきか
- AIコメントの誤認識・曖昧性:無条件に信頼せず、明確な根拠があるか確認する
- CI失敗条件の設計:AIが「バグの可能性あり」と出力した場合、CIをFailさせるべきか否か
AIのコメントをCIのブロッカーとするかどうかは慎重に設計する必要がある。
原則としてはFailではなく警告表示のみに留めることが望ましい。
理由は、AIコメントが誤認や推測ベースであることが多く、自動でFailさせると開発阻害要因になるため。
運用上の注意点
継続的に運用する際、以下のような点に注意する。
- LLMのバージョンや学習データの更新によって指摘傾向が変化するため、ログの蓄積が重要
- PRテンプレートやレビューポリシーに、AIコメントの取扱い方針を明記する必要がある
- 再現性の担保が難しいため、CIログは完全保存し、差分比較ができるようにする
まとめ
AIレビューをCI/CDフローに統合することは、コードレビューの自動化と品質向上に一定の効果を持つが、その設計・運用には慎重な配慮が求められる。
レビューアーの役割は、人間とAIのレビュー結果の重複・補完・不一致を検証しながら、信頼できるレビュー体制を築いていくことにある。
機械が生成するコメントに対して、そのまま鵜呑みにせず疑問を持つ姿勢こそが、レビューアーとしての成熟を支える。
AIの導入によってレビュー文化が変化する中でも、人間の判断力が求められる場面は今後も残り続けるだろう。